GSCL Research Talks
Die GSCL Research Talks, die zwischen Februar 2021 und Dezember 2022 stattfanden, boten ein Forum für den Austausch über aktuelle Forschungsthemen in der Wissenschaft und der Industrie. Zu den Vortragenden zählten hochrangige Forscher aus Wissenschaft und Industrie. Die Vorträge wurden auf Deutsch oder Englisch gehalten, wobei die Sprache jedes Vortrags im Voraus bekannt gegeben wurde. Die Veranstaltungsdauer betrug eine Stunde, einschließlich 30 Minuten Fragen und Antworten.
GSCL Tutorial Talks
Die 90minütigen GSCL Tutorial Talks behandelten spezielle Themen der Computerlinguistik, die normalerweise nicht im Lehrplan enthalten sind, Einblicke in Forschungsprojekte oder Einführungsvorträge in benachbarte Disziplinen. Die Reihe enthielt auch Interviews mit Experten über ihre persönlichen Erfahrungen und Präsentationen aus der industriellen Forschung. Die GSCL Tutorial Talks waren ein Forum für Studierende und Doktoranden, um sich mit Experten auszutauschen, sich über Praktikums- oder Einstellungsmöglichkeiten zu informieren und sich mit Experten und Kommilitonen anderer Universitäten zu vernetzen.
Michael Roth (Universität Stuttgart)
Abstract
When we use language, we usually assume that the meaning of
our statements is clear and that others can understand precisely this
meaning. However, that this may not always be the case is for example
demonstrated by vague statements in polit [mehr…]
Sebastian Schuster (Universität des Saarlandes)
Understanding longer narratives or participating in conversations requires tracking of discourse entities that have been mentioned. Indefinite noun phrases (NPs), such as ‘a dog’, frequently introduce discourse entities but this behavior is modulated [mehr…]
Alessandra Zarcone (Hochschule Augsburg)
Computational linguists have cared about data “before it was cool”. In the community of ML/AI practitioners, however, “model work” gets more love than the “data work”.
Small and medium business, while not immune to the AI hype, often (1) do not have [mehr…]
Natural Language Processing is one of the core areas of artificial intelligence. Currently, the majority of the research efforts in this area are mostly opting for better performance on major benchmarks and downstream tasks. However, it is vital to a [mehr…]
This is the second part of a two-part talk, in which Dr. Anne Lauscher will discuss their latest research centering around the current modeling of 3rd person pronouns in NLP as a concrete example.
Biography
Anne Lauscher is a postdoctoral researche [mehr…]
Seid Muhie Yimam (University of Hamburg)
The development of natural language processing and AI applications require a gold standard dataset. Data is the pillar of those intelligent applications, and an annotation is a way to acquire it. In this talk, I will first discuss the main components [mehr…]
Thomas Proisl (FAU Erlangen-Nürnberg)
The study of cooccurrences, i. e. the analysis of linguistic units that occur together, has had a profound impact on our view of language. In this talk, I will discuss how we can generalize established methods for the statistical analysis of two-word [mehr…]
The distinction between abstract and concrete words (such as “dream” in contrast to “banana”) is considered a highly relevant semantic categorisation for Natural Language Processing purposes. For example, previous studies have identified distribution [mehr…]
There are many technical approaches to mapping natural-language sentences to symbolic meaning representations. The current dominant approach is with neural sequence-to-sequence models which map the sentence to a string version of the meaning represen [mehr…]
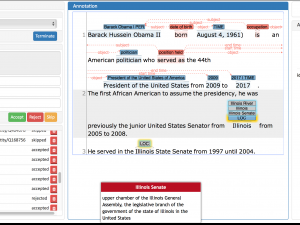
Let the computer actively help you to enrich your texts with annotations and to link your texts to knowledge bases – this is what the INCEpTION text annotation platform helps you with.
No matter if you work alone or in a team or if you want to provi [mehr…]
Important: If you are new to text annotation, this tutorial is a great preparation for our tutorial about the INCEpTION platform!
This tutorial guides you through the steps for manual annotation with the aim of text corpus construction for machine l [mehr…]
Alexander Fraser (Ludwig-Maximilians-Universität München)
Data-driven Machine Translation is an interesting application of machine-learning-based natural language processing techniques to multilingual data. Particularly with the recent advent of powerful neural network models, it has become possible to inco [mehr…]
Benjamin Roth (University of Vienna)
Deep learning relies on massive training sets of labeled examples to learn from – often tens of thousands to millions to reach peak predictive performance. However, large amounts of training data are only available for very few standardized learning [mehr…]
Daria Stepanova (Bosch Center for Artificial Intelligence)
Advances in information extraction have enabled the automatic construction of large knowledge graphs (KGs) like DBpedia, Freebase, YAGO and Wikidata. Learning rules from KGs is a crucial task for KG completion, cleaning and curation. This tutorial pr [mehr…]
Friedrich Faubel (Cerence Inc.)
This talk will take you on a journey into the world of speech enhancement, a realm that exists only to separate an acoustic target speech signal from noise, interfering speech or music. While classical approaches were typically quite heavy on the mat [mehr…]
Casey Redd Kennington (Boise State University)
Hallmarks of intelligence include the ability to acquire, represent, understand, and produce natural language. Although recent efforts in data-driven, machine learning, and deep learning methods have advanced natural language processing applications, [mehr…]